
It is the little things. The little things that can sometimes eat at you. And here is one of my little pet peeves. At some point – not sure how recently – NCBI changed the default database for Blastn searching to the “human G+T” database. This Db contains human genomic and transcriptomic data.
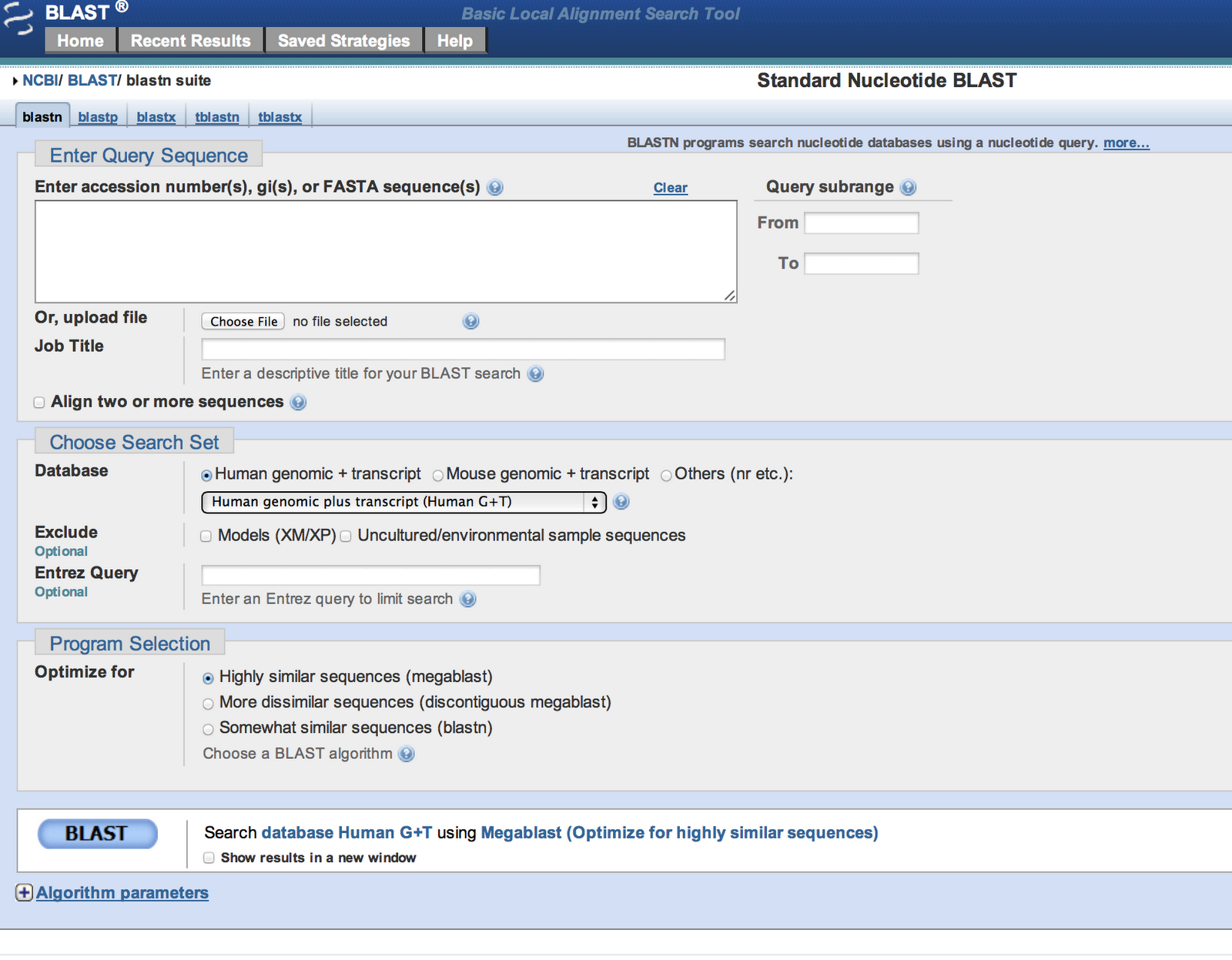
Now – I am extremely grateful for many – if not most – of the things NCBI does. Pubmed is great. Pubmed Central rocks. Sequence databases galore. And all sorts of widgets and tools associated with sequence analysis. Including a free blast server. Which I use a lot. But why? why is human G+T the default database for blastn searches? Why? I never only want to search this Db. Why not have the non redundant Db of everything be the default? Are there really that many people who only want to search human G+T? Or is this some ploy to force people to do such searches? This tiny little thing. This setting. This glitch. Whatever it is. It drives me batty …


I wrote NCBI about this when they changed it a few years ago… didn't get a response.
LikeLike
Well, maybe now we will get one …
LikeLike
They changed this awhile ago. I often use this questionable choice to my advantage when assigning homework or test questions to students by giving them a mystery sequence and seeing how many think/remember to check the specific database being searched when they do a blast search.
LikeLike
Having the default db be human is annoying, but if you log in and change the database selection, NCBI will remember your change and the next time the default db will be the one you chose.
Alternatively, you might bookmark the microbial genome blast page:
http://www.ncbi.nlm.nih.gov/blast/Blast.cgi?PAGE=MegaBlast&PROGRAM=blastn&BLAST_PROGRAMS=megaBlast&PAGE_TYPE=BlastSearch&BLAST_SPEC=MicrobialGenomes
LikeLike
Just another reason to switch to hmmer3!
LikeLike
I wonder how much that default reduces their server load. As tintmylf says, most people don't think about the default. If all those are just blasting against human, its probably a lot less intensive than mindlessly searching nr.
LikeLike
Talking about nr, I found recently a “funny” information there :
“””
Nucleotide Sequence Databases
nr
All GenBank + RefSeq Nucleotides + EMBL + DDBJ + PDB sequences (excluding HTGS0,1,2, EST, GSS, STS, PAT, WGS). No longer “non-redundant”.
“””
OK, NCBI: could you change this misleading name please? Something like “anr” (almost non-redundant”)…
LikeLike
Absolutely agree. Another pet peeve: default on for the “mask low complexity region” flag. I don't want my searches masked unless I ask for it. If they want to return BOTH the masked and unmasked versions, fine, but when a search fails JUST BECAUSE the sequence was masked, it is REALLY ANNOYING.
LikeLike