I saw this post by Craig Pikaard on Facebook and it brought back some memories:
New paper from my lab in which we identified the RNAs made by RNA Polymerase IV, an enzyme we discovered ~15 years ago. Took us more than ten years to find the little buggers, but we finally got ’em. The paper is “open access”, meaning that anyone can read it without paying a download fee or subscription. So have at it if you need a nap.

And the post included a link to a new paper in Elife. This brought back memories because I had a small part in the discovery (or more accurately, some post discovery analysis). So – let’s step into a time machine here provided by, well, me keeping all my email forever I guess.
It was September 2000. I was working as a faculty member at TIGR (The Institute for Genomic Research) and I was doing some evolutionary analysis of the Arabidopsis thaliana genome, for what would become my most highly cited paper: Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. And then on Sept 6 day I got an email from someone who I had gotten to know a little bit who was also analyzing the genome:
———————————-
9/6
Dear Jonathan,
In helping Mike Bevan search for the general transcription machinery, I’ve
stumbled across something odd that might also interest you given its
evolutionary implications.
There should be three related genes in the Arabidopsis genome (or more if
any of the genes are duplicated) encoding ~135 kd (2nd largest)
DNA-dependent RNA polymerase subunits – one each for pol I, II and III.
These subunits are similar and are clearly related to one another (also to
the B subunit of the single bacterial RNA polymerase) yet they have
distinct motifs that allow them to be placed in each class (pol I, II, or
III) based on clustal analysis with orthologs from other species. Anyway,
there ARE three distinct ~135 kd subunit genes in the thaliana genome and
based on multiple alignments vs. mouse, yeast, drosophila etc genes, and
clustal analysis to draw phylogenetic trees, one is clearly for pol II, and
one is clearly for pol III. The third paralog is strange- it does not group
with other pol I 135 kd subunits (from yeast, Drosophila, Euplotes, mouse,
C. elegans), nor with pol II or III subunits. In fact, it appears as an
outgroup even when archael subunits (e.g. Sulfolobus) are included in the
analysis: archael subunits are more closely related to the pol II second
largest subunit than the mystery subunit is to other pol I, II, or III
subunits. By BLAST searching Genbank, the mystery subunit does not match
anything better than eukaryotic 135 kd subunits and it doesn’t look like a
chloroplast or mitochondrial subunit. I’m wondering if a plant Pol I can
really be that weird.
Is this something you would be interested in looking at if I send you the
protein sequences for clustal analysis?
Cheers
Craig
Craig S. Pikaard
Associate Professor
Biology Department, Washington University
Campus Box 1137, One Brookings Drive
St. Louis, MO 63130
Now this certainly seemed interesting and as I was doing a variety of analyses of RNA polymerase homologs for some studies of the evolution of microbes, it was something I actually knew a little bit about. So I wrote back immediately:
Craig
This sounds quite interesting. I have found that for many of the DNA repair genes I have been looking at, the A. thaliana genes do show quite long branches, so long branches might be a possibility. A good phylogenetic analysis should be able to detemrine if that is the case. If you send me the sequences and/or an alignment, I would be happy to put them through a more deailed phylogenetic analysis.
Jonathan
Then, a few minutes later I got another email:
Hi Jonathan,
I’m pasting below the sequences I used for the multiple alignments (using
DNAStar), starting with the mystery gene and then known second subunits of
pol I, II, III, and archae.
Thanks for having a look at this.
Craig
———–
Arabidopsis mystery gene (from chromosome 3):
DEFINITION DNA-dependent RNA polymerase II [Arabidopsis thaliana].
ACCESSION BAB02021
A. thal chromosome III sequence. Does not group with pol I, II or III
despite its description. Two chromosome 3 P1 clones and two partial cDNAs
(that are the same)from developing seeds match it (see accessions below,
with match scores)
GSDB:S:3264005|AB020749|AB020749|Arabidopsis thaliana genomic D… 598 0.0
GSDB:S:4681131|AP000377|AP000377|Arabidopsis thaliana genomic D… 566 0.0
GSDB:S:1038672|Z19120|ATRNAPIIM|A.thaliana mRNA for RNA polymer… 504 e-142
GSDB:S:8430488|BE522782|BE522782|M28H12STM Arabidopsis developi… 171
1e-046
GSDB:S:8430529|BE522823|BE522823|M29C3STM Arabidopsis developin… 171
2e-041
mdvdeiesagqiniselgesflqtfckkaatsffeefglishqlnsynffiehglqnvfesfgdilvepsfdvikkkdgd
wryatvfkkivikhdkfktgqdeyvekeildvkkqdiligsipvmvksvlcktsekgkenckkgncafdqggyfvikgae
kvfiaqeqmctkrlwisnspwtvsfrsetkrnrfivrlsenekaedykimekvltvyflsteipvwllffalgvssdkea
mdliafdgddasitnsliasiheadavceafrcgnnaltyvehqikstkfppaesvddclrlylfpclqglkkkarflgy
mvkcllsayagkrkcenrdsfrnkrielagellereirvhlaharrkmtramqkqlsgdgdlkpiehyldasvitnglnr
afstgawshpfrkmervsgvvanlgranplqtlidlrrtrqqvlytgkvgdarhphpshwgrvcflstpdgencglvknm
sllglvstqglesvvemlftcgmeelmndtstplcgkhkvllngdwvglcadsesfvgelksrrrqselplemeikrdkd
dnevriftdagrllrpllvvenlhklkqdkptqypfkhlldqgileligieeeedcttawgikqllkepknythceldls
fllgvscaivpfanhdhgkrvlyqsqkhcqqaigfsstnpnircdtlsqqlfypqkplfktlaseclekevlfngqnaiv
avnvhlgynqedsivmnkaslergmfrseqirsykaevdtkdsekrkkmdelvqfgktyskigkvdsleddgfpfiganm
stgdivigrctesgadhsiklkhtergivqkvvlssndegknfaavslrqvrspclgdkfssmhgqkgvlgyleeqqnfp
ftiqgivpdivinphafpsrqtpgqlleaalskgiacpiqkkegssaaytkltrhatpfstpgvteiteqlhragfsrwg
nervyngrsgemmrslifmgptfyqrlvhmsenkvkfrntgpvhpltrqpvadrkrfggirfgemerdcliahgasanlh
erlftlsdssqmhicrkcktyanviertpssgrkirgpycrvcassdhvvrvyvpygakllcqelfsmgitlnfdtklc
———————————
Known Pol I ~135 kd subunits:
Yeast (S. cerevisae)
MSKVIKPPGQARTADFRTLERESRFINPPKDKSAFPLLQEAVQPHIGSFNALTEGPDGGLLNLGVKDIGEKVIFDGKPLN
SEDEISNSGYLGNKLSVSVEQVSIAKPMSNDGVSSAVERKVYPSESRQRLTSYRGKLLLKLKWSVNNGEENLFEVRDCGG
LPVMLQSNRCHLNKMSPYELVQHKEESDEIGGYFIVNGIEKLIRMLIVQRRNHPMAIIRPSFANRGASYSHYGIQIRSVR
PDQTSQTNVLHYLNDGQVTFRFSWRKNEYLVPVVMILKALCHTSDREIFDGIIGNDVKDSFLTDRLELLLRGFKKRYPHL
QNRTQVLQYLGDKFRVVFQASPDQSDLEVGQEVLDRIVLVHLGKDGSQDKFRMLLFMIRKLYSLVAGECSPDNPDATQHQ
EVLLGGFLYGMILKEKIDEYLQNIIAQVRMDINRGMAINFKDKRYMSRVLMRVNENIGSKMQYFLSTGNLVSQSGLDLQQ
VSGYTVVAEKINFYRFISHFRMVHRGSFFAQLKTTTVRKLLPESWGFLCPVHTPDGSPCGLLNHFAHKCRISTQQSDVSR
IPSILYSLGVAPASHTFAAGPSLCCVQIDGKIIGWVSHEQGKIIADTLRYWKVEGKTPGLPIDLEIGYVPPSTRGQYPGL
YLFGGHSRMLRPVRYLPLDKEDIVGPFEQVYMNIAVTPQEIQNNVHTHVEFTPTNILSILANLTPFSDFNQSPRNMYQCQ
MGKQTMGTPGVALCHRSDNKLYRLQTGQTPIVKANLYDDYGMDNFPNGFNAVVAVISYTGYDMDDAMIINKSADERGFGY
GTMYKTEKVDLALNRNRGDPITQHFGFGNDEWPKEWLEKLDEDGLPYIGTYVEEGDPICAYFDDTLNKTKIKTYHSSEPA
YIEEVNLIGDESNKFQELQTVSIKYRIRRTPQIGDKFSSRHGQKGVCSRKWPTIDMPFSETGIQPDIIINPHAFPSRMTI
GMFVESLAGKAGALHGIAQDSTPWIFNEDDTPADYFGEQLAKAGYNYHGNEPMYSGATGEELRADIYVGVVYYQRLRHMV
NDKFQVRSTGPVNSLTMQPVKGRKRHGGIRVGEMERDALIGHGTSFLLQDRLLNSSDYTQASVCRECGSILTTQQSVPRI
GSISTVCCRRCSMRFEDAKKLLTKSEDGEKIFIDDSQIWEDGQGNKFVGGNETTTVAIPFVLKYLDSELSAMGIRLRYNV
EPK
C. elegans
MDCDIASYHVDSFDFLVSKGCQFAAQAVPAEKFRLKNGDAVTMKFTSAQLHKPTLDTGAKLTSDTLPLLPAECRQRGLTY
AGNLKVGIDVHVNGSRLDIIEIILGKVPIMLRSEGCHLRGMSRKELVVAGEEPIEKGGYFIVNGSEKVIRLLIANRRNFP
IAIIRKTFKEKGKLFSEFGVMMRSVKENHTAVMMTLHYLDTGTMQLALQFRREIFYVPLMYIVKALTDKNDAVISAGFKR
GRNQDQFYSSCILNMLAQCQEEEILNQEAAIRAIGSRFRVAVSDRVAPWEDDLEAGRFIIRECVLIHLDSDEEKFHTLAY
MTQKLIALVKGECAPETPDNPQFQEASVSGHILLLILRERMENIIGMVRRKLEYMSSRKDFILTSAAILKALGNHTGGEI
TRGMAYFLATGNLVTRVGLALQQESGFSVIAERINQLRFVSHFRAIHRGAFFMEMRTTDVRKLRPEAWGFICPVHTPDGA
PCGLLNHVTASCRIVTDLSDNSNVPSLLAELGMYTHKTVALAPPGEELYPVLMNGRFLGYVPITKAASIERYLRCAKVAK
DARIPYTSEIALVRRSTDIKNIQTQYPGIYILSDAGRLIRPVRNLAMDAVEHIGTFEQVYLSVVLDPEEAEPGVTMHQEL
HPSCLFSFAGNLIPFPDHNQSPRNVYQCQMGKQTMGTAVHAWHSRADNKMYRLQFPQQPMLKLEAYEKYEMDEYPLGTNA
CVAVISYTGYDMEDAMTINKASYQRGFAHGTVIKVERINLVTERERKTIFYRNPREEIKTVGPDGLPIPGRRYFLDEVYY
VTFNMETGDFRTHKFHYAEPAYCGLVRIVEQGEGDSGAKHALIQWRIERNPIIGDKFASRHGQKGINSFLWPVESLPFSE
TGMVPDIIFNPHGFPSRMTIGMMIESMAGKAAATHGENYDASPFVFNEDNTAINHFGELLTKAGYNYYGNETFYSGVDGR
QMEMQIFFGIVYYQRLRHMIADKFQVRATGPIDPITHQPVKGRKKGGGIRFGEMERDAIIAHGTSFVLQDRLLNCSDRDV
AYACRRCGSLLSVLMSSRAGSHLLKKKRKDDEPLDYTETQRCRTCDKDDQVFLLQVPRVFRYLTAELAAMNVKIKLGIEH
PSKVTGS
D. melanogaster
MLEEMQQMKTIPVLTNSRPEFKQIPKKLSRHLANLGGPHVDSFDEMLTVGLDNSAKHMIPNHWLSPAGEKISMKVESIWI
AKPKVPQDVIDVRTREIYPTDSRQLHVSYSGMCSVRLGWSVNGVQKTPINMDLGEVPIMLRSKACNLGQATPEEMVKHGE
HDSEWGGIFVIRGNEKIVRMLIMTRRNHPICVKRSSWKDRGQNFSDLGMLVQTVREDESSLSNVVHYLNNGTAKFMFSHV
KRLSYVPVCLILKCLMDYTDEEIYNRLVQGYESDQYYVSCVQAMLREVQNENVYTHAQCKSFIGNLFRARFPEVPEWQPD
DDVTDFILRERVMIHLDTYEDKFQLIVFMIQKLFQCAQGKYKVENVDSSMMQEVLLPGHLYQKYLSERVESWVSQVRRCL
QKKLTSPDALVTSAVMTQCMRQAGGVGRAIESFLATGNIASRTGLGLMQNSGLVIMAENINRMRYMSHFRAIHRGSYFTT
MRTTEARQLLPDAWGFICPVHTPDGTPCGLLNHLTLTCEISMRPDPKLVKAIPKHLIDMGMMPLSNRRYLGEKLYVVFLD
GKHLGHIHQSEAEKIVDELRYGKIFGTLPQMMEIGFIPFKKNGQFPGLYIATGPARLMRPVWNLKWKRVEYIGTLEQLYM
EIAIDAKEMYPDFTTHLELAKTHFMSNLANLIPMPDYNQSPRNMYQCQMGKQTMGTPCLNWPKQAANKLYRLQTPGTPLF
RPVHYDIIQLDDFAMGTNAIVAVISYTGYDMEDAMIINKAAYERGFAYGSIYKTKFLTLDKKSSYFARHPHMPELIKHLD
TDGLPHPGSKLSYGSPLYCYFDGEVATYKVVKMDEKEDCIVESIRQLGSFDLSPTKMVAITLRVPRPATIGDKFASRAGQ
KGICSQKYPAEDLPFTESGLIPDIVFNPHGFPSRMTIAMMIETMAGKGAAIHGNVYDATPFRFSEENTAIDYFGKMLEAG
GYNYYGTERLYSGVDGREMTADIFFGVVHYQRLRHMVFDKWQVRSTGAVEARTHQPIKGRKRGGGVRFGEMERDALISHG
AAFLLQDRLFHNSDKTHTLVCHKCGSILAPLQRIVKRNETGGLSSQPDTCRLCGDNSSVSMIEIPFSFKYLVTELSSVNI
NARFKLNEI
mouse
MDVDGRWRNLPSGPSLKHLTDPSYGIPPEQQKAALQDLTRAHVDSFNYAALEGLSHAVQAIPPFEFAFKDERISLTIVDA
VISPPSVPKGTICKDLNVYPAECRGRKSTYRGRLTADISWAVNGVPKGIIKQFLGYVPIMVKSKLCNLYNLPPRVLIEHH
EEAEEMGGYFIINGIEKVIRMLIEPRRNFPVAMVRPKWKSRGLGYTQFGVSMRCVREEHSAVNMNLHYVENGTVMLNFIY
RKELFFLPLGFALKALVSFSDYQIFQELIKGKEEDSFFRNSVSQMLRIVIEEGCHSQKQVLNYLGECFRVKLSLPDWYPN
VEAAEFLLNQGICIHLQSNTDKFYLRCLMTRKLFALARGECMDDNPDSLVNQEVLSPGQLFLMFLKEKMENWLVSIKIVL
DKRAQKANVSINNENLMKIFSMGTELTRPFEYLLATGNLRSKTGLGFLEDSGLCVVADKLNFLRYLSHFRCVHRGAAFAK
MRTTTVRRLLPESWGFLCPVHTPDGAPCGLLNHLTAVCEVVTKFGDTASIPALLCGLGVTGADTAPCRPYSDCYPVLLDG
VMVGWVDKDLAPEVADTLRRFKVLREKRIPPWMEVALIPMTGKPSLYPGLFLFTTPCRLVRPVQNLELGREELIGTMEQL
FMNVAIFEDEVFGGISTHQELFPHSLLSVIANFIPFSDHNQSPRNMYQCQMGKQTMGFPLLTYQNRSDNKLYRLQTPQSP
LVRPCMYDFYDMDNYPIGTNAIVAVISYTGYDMEDAMIVNKASWERGFAHGSVYKSEFIDLSEKFKQGEDNLVFGVKPGD
PRVMQKLDDDGLPSIGAKLEYGDPYYSYLNLNTGEGFVVYYKSKENCVVDNIKVCSNDMGSGKFKCICITVRIPRNPTIG
DKFASRHGQKGILSRLWPAEDMPFTESGMMPDILFNPHGFPSRMTIGMLIESMAGKSAALHGLCHDATPFIFSEENSALE
YFGEMLKAAGYNFYGTERLYSGISGMELEADIFIGVVYYQRLRHMVSDKFQVRTTGARDKVTNQPLGGRNVQGGIRFGEM
ERDALLAHGTSFLLHDRLFNCSDRSVAHVCVECGSLLSPLLEKPPPSWSAMRNRKYNCTVCGRSDTIDTVSVPYVFRYFV
AELAAMNIKVKLDVI
Euplotes
MKTNAKFDRKEISKIYKNIARHHIDSFDFAMSTCLNRACEHMLPFDYIVPEESASCGFKKLTLWYDSFELGQPSLGEIDY
DSHILYPSECRQRKMTYTIPLFATIFKKFDDEMVDNFKVKLGDIPTMGRKKFCNLKGLTKKELAKRGEDMLEFGGYFIVN
GNEKVIRMLIVPKRNFPIAFKRSKFLERGKDFTDYGVQMRCVRDDFTAQTITLTYLSDGSVSLRLIYQKQEFLIPIILIL
KALKNCTDRQIYERIVKGNFNQRQISDRVEAILAVGKDLNIYDSDQSKALIGSRFRIVLAGITSETSDIDAGDLFLSKHI
CIHTDSYEAKFDTLILMIDKLYASVANEVELDNLDSVAMQDVLLGGHLYLQILSEKLFDCLHINLRARLNKELKRHNFDP
MKFRDVLTNQKINCGIGLIGKRMENFLATGNLISRTNLDLMQTSGFCIIGDKLNNIRFLSHFRSIHRGQYFAEQKTTSVR
KLLPESWGFICPVHTPDGAPCGLLNHISMSCVPIGSEEKQIDIDKFRNILGELGMNSISSDLCLNYHTGYYPVIFDGIHL
GYVEKDIGESFVEGLRYLKCTQSQPDYAIPRTLEIAFIPFSGYSRNLQWPGIFLASTPARFTRPVKNLHYNCIEWISPLE
QMNLSIACTDEDITPETTHQELDPINILSIVASVGVFAEYNQSPRNMYQCQMAKQTMGTPYHNHQFRTDNKIYRLLFPHR
PIVKTRTQVDFDIEEYPSGTNAVVAVISYTGYDLEDAMIINKSSYERGFGHGVVYKSYTHDLNESNSQSTRGIKSSVRYK
FLNNVSQKDKSKIKLENIDPDGLPKIGSQLTKGKPELCIFDTLKRGAKLSKFKDSEKARIETVRVCGNDDKNPDNLSIGY
TIRYSRIPVIGDKFSSRHGQKGVLSVLWPQVDMPFTENGITPDLIINPHAFPSRMTMGMLIQSMAAKSGSLRGEFKTVET
FQRYDDNDIVGHFGKELLDKGFNYHGNELMYSGIFGTPLKADIFIGVVYYQRLRHMVSDKSQARGTGPIDILTHQPVKGR
KKGGGIRFGEMERDSLLAHGAAYCLNDRLFRSSDYSEGFVCQNCGSILSCYVNRAIMKTQTFIPPSLDESNKDTEDKEIH
MNEKVICKVCKKNSNCKKVALPFVLRFLANELASMGIKLKFTVNDF
——————–
Pol II second largest subunits
S. cerevisae
msdlansekyydedpygfedesapitaedswavisaffrekglvsqqldsfnqfvdytlqdiicedstlileqlaqhtte
sdnisrkyeisfgkiyvtkpmvnesdgvthalypqearlrnltyssglfvdvkkrtyeaidvpgrelkyeliaeesedds
esgkvfigrlpimlrskncylseatesdlyklkecpfdmggyfiingsekvliaqersagnivqvfkkaapspishvaei
rsalekgsrfistlqvklygregssartikatlpyikqdipiviifralgiipdgeilehicydvndwqmlemlkpcved
gfviqdretaldfigrrgtalgikkekriqyakdilqkeflphitqlegfesrkafflgyminrlllcaldrkdqddrdh
fgkkrldlagpllaqlfktlfkkltkdifrymqrtveeahdfnmklainaktitsglkyalatgnwgeqkkamssragvs
qvlnrytysstlshlrrtntpigrdgklakprqlhnthwglvcpaetpegqacglvknlslmscisvgtdpmpiitflse
wgmepledyvphqspdatrvfvngvwhgvhrnparlmetlrtlrrkgdinpevsmirdirekelkiftdagrvyrplfiv
eddeslghkelkvrkghiaklmateyqdieggfedveeytwssllneglveyidaeeeesiliamqpedlepaeaneend
ldvdpakrirvshhattfthceihpsmilgvaasiipfpdhnqsprntyqsamgkqamgvfltnynvrmdtmanilyypq
kplgttrameylkfrelpagqnaivaiacysgynqedsmimnqssidrglfrslffrsymdqekkygmsitetfekpqrt
ntlrmkhgtydkldddgliapgvrvsgedviigkttpispdeeelgqrtayhskrdastplrstengivdqvlvttnqdg
lkfvkvrvrttkipqigdkfasrhgqkgtigityrredmpftaegivpdliinphaipsrmtvahliecllskvaalsgn
egdaspftditvegiskllrehgyqsrgfevmynghtgkklmaqiffgptyyqrlrhmvddkiharargpmqvltrqpve
grsrdgglrfgemerdcmiahgaasflkerlmeasdafrvhicgicglmtviaklnhnqfeckgcdnkidiyqihipyaa
kllfqelmamnitprlytdrsrdf
C. elegans
myddedemvndpmdgdyiddsdeisaeawqeacwvvisayfdekglvrqqldsfdefvqmnvqrivedsppvelqsenqh
lgtdmenpakfslkfnqiylskpthwekdgapmpmmpnearlrnltyasplyvditkvvtrddsatekvydkvfvgkvpv
mlrssycmlsnmtdrdltelnecpldpggyfvingsekvliaqekmatntvyvfsmkdgkyafktecrsclenssrptst
mwvnmlargggggkktamgqriigilpyikqeipimivfralgfvsdrdilghiiydfndpemmemvkpsldeafviqeq
nvalnfigargakpgvtreqrikyareilqkellphvgvsehcetkkaffigymvhrlllaalgrrelddrdhignkrld
lagpllaflfrslfrnllkemrmtaqkyinknddfaldvcvktstitrgltyslatgnwgdqkkahqsragvsqvlnrlt
ytatlshlrranspigregklakprqlhntqwgmvcpaetpegqavglvknlalmayisvgslpepilefleewsmenle
evspsaiadatkifvngawvgihrepdqlmttlkklrrqmdiivsevsmvrdirdreiriytdagrvcrpllivenqkla
lkkrhidqlkeaadeankytwsdlvgggvvelidsmeeetsmiammpedlrsggycdththceihpamilgvcasiipfp
dhnqsprntyqsamgkqamgvyttnfhvrmdtlahvlyypqkplvttrsmeylrfnelpaginaivailsysgynqedsv
imnnsaidrglfrsvfyrsyrdneanldnaneeliekptrekcsgmrhslydkldedgiispgmrvsgddviigktvalp
didddldasgkkypkrdastflrssetgivdqvmlslnsdgnkfvkirmrsvrlpqigdkfasrhgqkgtmgimyrqedm
pftaegltpdiiinphavpsrmtighlieclqgklsankgeigdatpfndtvnvqkisgllceygyhlrgnevmynghtg
kklttqiffgptyyqrlkhmvddkihsrargpiqmmnrqpmegrardgglrfgemerdcqishgatqflrerlfevsdpy
hvyvcnncglivvanlrtnsfeckacrnktqvsavripyackllfqelmsmsiaprlmvkprqskrskhqsea
Drosophila
msvqrivedspaielqaerqhtsgevetpprfslkfeqiylskpthwekdgspspmmpnearlrnltysaplyvditktk
nvegldpvetqhqktfigkipimlrstycllsqltdrdltelnecpldpggyfiingsekvliaqekmatntvyvfsmkd
gkyafkteirsclehssrptstlwvnmmargsqnikksaigqriiailpyikqeipimivfralgfvadrdilehiiydf
ddpemmemvkpsldeafvvqeqnvalnfigargarpgvtkdkrikyakeilqkemlphvgvsdfcetkkayflgymvhrl
llaslgrrelddrdhygnkrldlagpllaflfrglfknlmkevrmytqkfidrgkdfnlelaiktniitdglryslatgn
wgdqkkahqaragvsqvlnrltfastlshlrrvnspigrdgklakprqlhntlwgmlcpaetpegaavglvknlalmayi
svgsqpspilefleewsmenleeiapsaiadatkifvngcwvgihrdpeqlmatlrklrrqmdiivsevsmirdirdrei
riytdagricrpllivengslllkkthvemlkerdyknyswqvlvasgvveymytleeetvmiamspydlkqdkdyayct
tythceihpamilgvcasiipfpdhnqsprntyqsamgkqamgvyitnfhvrmdtlahvlyypmkplvttrsmeylrfre
lpaginsivailcytgynqedsvilnasavergffrsvfyrsykdsenkrvgdqeenfekphrgtcqgmrnahydklddd
giiapgirvsgddvvigktitlpenddeldsntkrfskrdastflrnsetgivdqvmltlnsegykfckirvrsvripqi
gdkfasrhgqkgtcgiqyrqedmaftceglapdiiinphaipsrmtighlieclqgklgsnkgeigdatpfndavnvqki
stflqeygyhlrgnevmynghtgrkinaqvflgptyyqrlkhmvddkihsrargpvqilvrqpmegrardgglrfgemer
dcqishgaaqflrerlfevsdpyrvhicnfcgliaianlrnntfeckgcknktqisqvrlpyaakllfqelmsmniaprl
mvt
Human
mydadedmqydedddeitpdlwqeacwivissyfdekglvrqqldsfdefiqmsvqrivedappidlqaeaqhasgevee
ppryllkfeqiylskpthwerdgapspmmpnearlrnltysaplyvditktvikegeeqlqtqhqktfigkipimlrsty
cllngltdrdlcelnecpldpggyfiingsekvliaqekmatntvyvfakkdskyaytgecrsclenssrptstiwvsml
arggqgakksaigqrivatlpyikqevpiiivfralgfvsdrdilehiiydfedpemmemvkpsldeafviqeqnvalnf
igsrgakpgvtkekrikyakevlqkemlphvgvsdfcetkkayflgymvhrlllaalgrrelddrdhygnkrldlagpll
aflfrgmfknllkevriyaqkfidrgkdfnlelaiktriisdglkyslatgnwgdqkkahqaragvsqvlnrltfastls
hlrrlnspigrdgklakprqlhntlwgmvcpaetpeghavglvknlalmayisvgsqpspilefleewsmenleeispaa
iadatkifvngcwvgihkdpeqlmntlrklrrqmdiivsevsmirdirereiriytdagricrpllivekqklllkkrhi
dqlkereynnyswqdlvasgvveyidtleeetvmlamtpddlqekevaycstythceihpsmilgvcasiipfpdhnqsp
rntyqsamgkqamgvyitnfhvrmdtlahvlyypqkplvttrsmeylrfrelpaginsivaiasytgynqedsvimnrsa
vdrgffrsvfyrsykeqeskkgfdqeevfekptretcqgmrhaiydkldddgliapgvrvsgddviigktvtlpenedel
estnrrytkrdcstflrtsetgivdqvmvtlnqegykfckirvrsvripqigdkfasrhgqkgtcgiqyrqedmpftceg
itpdiiinphaipsrmtighlieclqgkvsankgeigdatpfndavnvqkisnllsdygyhlrgnevlyngftgrkitsq
ifigptyyqrlkhmvddkihsrargpiqilnrqpmegrsrdgglrfgemerdcqiahgaaqflrerlfeasdpyqvhvcn
lcgimaiantrthtyecrgcrnktqislvrmpyackllfqelmsmsiaprmmsv
Peperomia (Plant)
wgmmcpaetpegqacglvknlalmvyitvgsaanpilefleewstenfeeispavipqatkifvngcwvgihrnpdllvk
tlrqlrrqidvntevgvirdirlkelrlytdygrcsrplfivenqkllikkrdiqalqqretqeegwhflvskgfieyvd
teeeettmismtindlvqarrskdaysttythceihpslilgvcasiipfpdhnqsprntyqsamgkqamgiyvtnyqlr
mdtlayvlyypqkplvttramehlhfrqlpaginaivaiacysgynqedsvimnqssidrgffrslffrsyrdeekkmgt
lvkedfgrpnrentmgmrhgsydkldddglappgtrvsgedviigktspiaqdesqgqasrynrrdhstslrhsesgmvd
qvllttnadglrfvkvrmrsvripqigdkfssrhgqkgtvgmtytqedmpwtaegitpdiivnqhaipsrmtigqlieci
mgkvaahmgkegdatpftdvtvdniskalhkcgyqmrgfetmynghtgrrlsamiflgptyyqrlkhmvddkih
Arabidopsis
Columbia; BAC clone F17L22.
Essentially identical to Larkin and Guilfoyle sequence for pol II 2nd
largest subunit
MEYNEYEPEPQYVEDDDDEEITQEDAWAVISAYFEEKGLVRQQLDSFDEFIQNTMQEIVDESADIEIRPESQHNPGHQSD
FAETIYKISFGQIYLSKPMMTESDGETATLFPKAARLRNLTYSAPLYVDVTKRVIKKGHDGEEVTETQDFTKVFIGKVPI
MLRSSYCTLFQNSEKDLTELGECPYDQGGYFIINGSEKVLIAQEKMSTNHVYVFKKRQPNKYAYVGEVRSMAENQNRPPS
TMFVRMLARASAKGGSSGQYIRCTLPYIRTEIPIIIVFRALGFVADKDILEHICYDFADTQMMELLRPSLEEAFVIQNQL
VALDYIGKRGATVGVTKEKRIKYARDILQKEMLPHVGIGEHCETKKAYYFGYIIHRLLLCALGRRPEDDRDHYGNKRLDL
AGPLLGGLFRMLFRKLTRDVRSYVQKCVDNGKEVNLQFAIKAKTITSGLKYSLATGNWGQANAAGTRAGVSQVLNRLTYA
STLSHLRRLNSPIGREGKLAKPRQLHNSQWGMMCPAETPEGQACGLVKNLALMVYITVGSAAYPILEFLEEWGTENFEEI
SPSVIPQATKIFVNGMWVGVHRDPDMLVKTLRRLRRRVDVNTEVGVVRDIRLKELRIYTDYGRCSRPLFIVDNQKLLIKK
RDIYALQQRESAEEDGWHHLVAKGFIEYIDTEEEETTMISMTISDLVQARLRPEEAYTENYTHCEIHPSLILGVCASIIP
FPDHNQSPRNTYQSAMGKQAMGIYVTNYQFRMDTLAYVLYYPQKPLVTTRAMEHLHFRQLPAGINAIVAISCYSGYNQED
SVIMNQSSIDRGFFRSLFFRSYRDEEKKMGTLVKEDFGRPDRGSTMGMRHGSYDKLDDDGLAPPGTRVSGEDVIIGKTTP
ISQDEAQGQSSRYTRRDHSISLRHSETGMVDQVLLTTNADGLRFVKVRVRSVRIPQIGDKFSSRHGQKGTVGMTYTQEDM
PWTIEGVTPDIIVNPHAIPSRMTIGQLIECIMGKVAAHMGKEGDATPFTDVTVDNISKALHKCGYQMRGFERMYNGHTGR
PLTAMIFLGPTYYQRLKHMVDDKIHSRGRGPVQILTRQPAEGRSRDGGLRFGEMERDCMIAHGAAHFLKERLFDQSDAYR
VHVCEVCGLIAIANLKKNSFECRGCKNKTDIVQVYIPYACKLLFQELMSMAIAPRMLTKHLKSAKGRQ
—————–
RNA polymerase III
Yeast (cerevisae)
mvaatkrrkthihkhvkdeafddllkpvykgkkltdeintaqdkwhllpaflkvkglvkqhldsfnyfvdtdlkkiikan
qlilsdvdpefylkyvdirvgkksssstkdyltpphecrlrdmtysapiyvdieytrgrniimhkdveigrmpimlrsnk
cilydadeskmaklnecpldpggyfivngtekvilvqeqlsknriiveadekkgivqasvtsstherksktyvitkngki
ylkhnsiaeeipiaivlkacgilsdleimqlvcgndssyqdifavnleesskldiytqqqaleyigakvktmrrqkltil
qegieaiattviahltvealdfrekalyiammtrrvvmamynpkmiddrdyvgnkrlelagqlisllfedlfkkfnndfk
lsidkvlkkpnrameydallsinvhsnnitsglnraistgnwslkrfkmeragvthvlsrlsyisalgmmtrissqfeks
rkvsgpralqpsqfgmlctadtpegeacglvknlalmthittddeeepikklcyvlgveditlidsaslhlnygvylngt
ligsirfptkfvtqfrhlrrtgkvsefisiysnshqmavhiatdggricrpliivsdgqsrvkdihlrklldgeldfddf
lklglveyldvneendsyialyekdivpsmthleiepftilgavaglipyphhnqsprntyqcamgkqaigaiaynqfkr
idtllylmtypqqpmvktktielidydklpagqnatvavmsysgydiedalvlnkssidrgfgrcetrrktttvlkryan
htqdiiggmrvdengdpiwqhqslgpdglgevgmkvqsgqiyinksvptnsadapnpnnvnvqtqyreapviyrgpepsh
idqvmmsvsdndqalikvllrqnrrpelgdkfssrhgqkgvcgiivkqedmpfndqgivpdiimnphgfpsrmtvgkmie
lisgkagvlngtleygtcfggskledmskilvdqgfnysgkdmlysgitgeclqayiffgpiyyqklkhmvldkmharar
gpravltrqptegrsrdgglrlgemerdcviaygasqlllerlmissdafevdvcdkcglmgysgwcttcksaeniikmt
ipyaakllfqellsmniaprlrledifqq
S. pombe
mgvntagdpqksqpkinkggigkdesfgalfkpvykgkkladpvptiedkwqllpaflkvkglvkqhldsynyfvdvdlk
kivqanekvtsdvepwfylkyldirvgapvrtdadaiqasisphecrlrdltyganiyvdieytrgkqvvrrrnvpigrm
pvmlrsnkcvlsgknememaalnecpldpggyfivkgtekvilvqeqlsknriiveaepkkglwqasvtsstherkskty
vitkngklylkhnsvaddipivvvlkamglqsdqeifelvagaeasyqdlfapsieecaklniytaqqaleyigarvkvn
rraganrlppheealevlaavvlahinvfnlefrpkavyigimarrvlmamvdplqvddrdyvgnkrlelagqllallfe
dlfkkfnsdlklnidkvlkkphrtqefdaynqltvhsdhitqgmvralstgnwslkrfkmeragvthvlsrlsyisalgm
mtritsqfektrkvsgprslqasqfgmlctsdtpegeacglvknlalmthittdeeeepiiklayafgiedihvisgrel
hshgtylvylngailgisrypslfvasfrklrrsgkispfigifinthqravfistdggricrpliivqnglpkveskhi
rllkegkwgfedflkqglveyvdvneendslisvyerditpdtthleiepftilgavaglipyphhnqsprntyqcamgk
qaigaiaynqlqridtllylmvypqqpmvktktieligydklpagqnatvaimsysgydiedalvlnkssidrgfgrcqv
fhkhsvivrkypngthdrigdpqrdpetgevvwkhgvveddglagvgcrvqpgqiyvnkqtptnaldnsitlghtqtves
gykatpmtykapepgyidkvmltttdsdqtlikvlmrqtrrpelgdkfssrhgqkgvcgvivqqedmpfndqgicpdiim
nphgfpsrmtvgkmiellsgkvgvlrgtleygtcfggtkvedasrilvehgynysgkdmltsgitgetleayifmgpiyy
qklkhmvmdkmharargpravltrqptegrsrdgglrlgemerdcliaygasqlllerlmissdacdvdvcgqcgllgyk
gwcnscqstrevvkmtipyaakllfqellsmnivprlaledefky
Drosophila
mvelkmgdhnveattwdpgdskdwsvpikpltekwklvpaflqvkglvkqhidsfnhfinvdikkivkanelvtsgadpl
fylkyldvrvgkpdiddgfnitkattphecrlrdttysapitvdieytrgtqrikrnnlligrmplmlrsncaltgksef
elsklnecpldpggyfvvrgqekviliqeqlswnkmltedfngvvqcqvtssthekksrtlvlskhgkyylkhnsmtddi
pivvifkalgvvsdqeiqsligidsksqnrfgaslidaynlkvftqqraleymgsklvvkrfqsattktpseearelllt
tilahvpvdnfnlqmkaiyvsmmvrrvmaaeldktlfddrdyygnkrlelagsllsmmfedlfkrmnwelktiadknipk
vkaaqfdvvkhmraaqitaglesaissgnwtikrfkmeragvtqvlsrlsyisalgmmtrvnsqfektrkvsgprslqps
qwgmlcpsytpegeacglvknlalmthitteveerpvmivafnagvedirevsgnpinnpnvflvfingnvlgltlnhkh
lvrnlrymrrkgrmgsyvsvhtsytqrciyihtdggrlcrpyvivenrrplvkqhhldelnrgirkfddflldglieyld
vneendsfiawnedqiedrtthleietftllgvcaglvpyphhnqsprntyqcamgkqamgmigynhnnridslmynlvy
phapmvksktieltnfdklpagqnatvavmsysgydiedalilnkasidrgygrclvyknskctvkryanqtfdrimgpm
kdaltnkvifkhdvldtdgivapgeqvqnkqiminkempavtsmnplqgqsaqvpytavpisykgpepsyiervmvsana
eedflikillrqtriprgdkfssrhgqkgvtgliveqedmpfndfgicpdmimnphgfpsrmtvgktlellggkaglleg
kfhygtafggskvediqaelerhgfnyvgkdffysgitgtpleayiysgpvyyqklkhmvqdkmharargpkavltrqpt
qgrsregglrlgemerdclisygasmlimerlmissdafevdvcrtcgrmaycswchfcqssanvskismpyackllfqe
ltsmnvvpkmileny
A. thaliana (chromosome 5)
DEFINITION DNA-directed RNA polymerase subunit [Arabidopsis thaliana].
ACCESSION BAB11387
mliiflhgfqitdsliaklramgldqedldltnddhfidkeklsapikstadkfqlvpeflkvrglvkqhldsfnyfinv
gihkivkansritstvdpsiylrfkkvrvgepsiinvntveninphmcrladmtyaapifvnieyvhgshgnkaksakdn
viigrmpimlrscrcvlhgkdeeelarlgecpldpggyfiikgtekvlliqeqlsknriiidsdkkgninasvtsstemt
ksktviqmekekiylflhrfvkkipiiivlkamgmesdqeivqmvgrdprfsasllpsieecvsegvntqkqaldyleak
vkkisygtppekdgralsilrdlflahvpvpdnnfrqkcfyvgvmlrrmieamlnkdamddkdyvgnkrlelsgqlisll
fedlfktmlseaiknvdhilnkpirasrfdfsqclnkdsrysislglertlstgnfdikrfrmhrkgmtqvltrlsfigs
mgfitkispqfeksrkvsgprslqpsqwgmlcpcdtpegescglvknlalmthvttdeeegplvamcyklgvtdlevlsa
eelhtpdsflvilnglilgkhsrpqyfanslrrlrragkigefvsvftnekqhcvyvasdvgrvcrplviadkgisrvkq
hhmkelqdgvrtfddfirdglieyldvneennalvclraeaakadtthieiepftilgvvaglipyphhnqsprntyqca
mgkqamgniaynqlnrmdtllyllvypqrpllttrtielvgydklgagqnatvavmsfsgydiedaivmnkssldrgfgr
civmkkivamsqkydnctadrilipqrtgpdaekmqildddglatpgeiirpndiyinkqvpvdtvtkftsalsdsqyrp
areyfkgpegetqvvdrvalcsdkkgqlcikyiirhtrrpelgdkfssrhgqkgvcgiiiqqedfpfselgicpdlimnp
hgfpsrmtvgkmiellgskagvscgrfhygsafgersghadkvetisatlvekgfsysgkdllysgisgepveayifmgp
iyyqklkhmvldkmhargsgprvmmtrqptegkskngglrvgemerdcliaygasmliyerlmissdpfevqvcracgll
gyynyklkkavcttckngdniatmklpyackllfqvktiglffklklstsshlendkiilisgykflpkisknh
———————
Archae second subunit (only one polymerase, though multi-subunit similar to
eukaryotes)
Sulfolobus
DEFINITION DNA-DIRECTED RNA POLYMERASE SUBUNIT B.
ACCESSION P11513
PID g133422
mldtesrwaiaesffktrglvrqhldsfndflrnklqqviyeqgeivtevpglkiklgkiryekpsiretdkgpmreitp
mearlrnltysspiflsmipvenniegepieiyigdlpimlksvadptsnlpidklieigedpkdpggyfivngsekmii
aqedlatnrvlvdygksgsnithvakvtssaagyrvqvmierlkdstiqisfatvpgripfaiimralgfvtdrdivyav
sldpqiqnellpsleqassitsaeealdfignrvaigqkrenriqkaeqvidkyflphlgtspedrkkkgyylasavnki
lelylgrrepddkdhyankrvrlagdlftslfrvafkafvkdlvyqlekskvrgrrlsltalvradiiterirhalatgn
wvggrtgvsqlldrtnwlsmlshlrrvvsslargqpnfeardlhgtqwgrmcpfetpegpnsglvknlallaqvsvgine
svvervayelgvvsvedvirriseqnedvekymswskvylngrllgyyedgkelakkiresrrqgklsdevnvayiatdy
lnevhincdagrvrrpliivnngtplvdtedikklkngeitfddlvkqgkiefidaeeeenayvalnpqdltpdhthlei
wpsailgiiasiipypehnqsprntyqsamakqslglyasnyqirtdtrahllhypqmplvqtrmlgvigyndrpagana
ilaimsytgynmedsiimnkssiergmyrstffrlysteevkypggqedkivtpeagvkgykgkdyyrlledngvvspev
evkggdvligkvspprflqefkelspeqakrdtsivtrhgengivdlvlitetlegnklvkvrvrdlripeigdkfatrh
gqkgvvgilidqvdmpytakgivpdiilnphalpsrmtigqimeaiggkyaalsgkpvdatpfletpklqemqkeilklg
hlpdstevvydgrtgqklksrilfgivyyqklhhmvadkmharargpvqiltrqptegraregglrfgemerdcligfgt
amlikdrlldnsykavvyicdqcgyvgwydrsknryvcpvhgdksvlhpvtvsyafklliqelmsmvisprlilgekvnl
ggasne
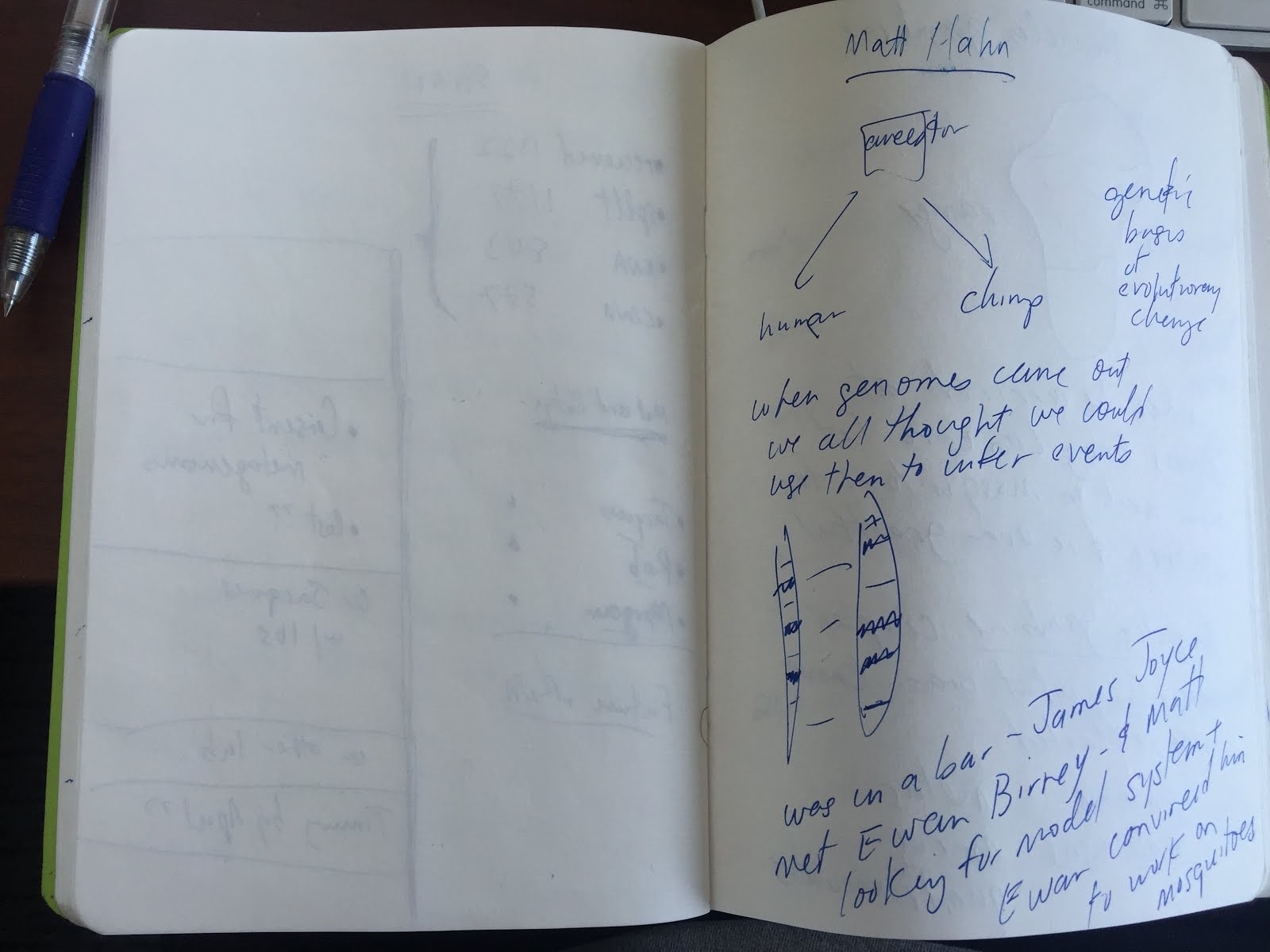
Well, this was helpful. Sequences and useful notes about them. So I played around with the sequences and searched for some other homologs and built a few alignments, build some masks to filter out poorly aligned regions, and then fed the data into PAUP and built a tree. (I note – I know about this because amazingly I still have all the files)
And I wrote back to Mike Bevan and Craig on Sept 8:
Mike and Craig
Attached is a phylogenetic tree of RNA polymerase subunits (Craig suggested I look at these because of an unusual protein in the A. thaliana genome). A. thaliana has representatives in five different subfamilies – Pol-I, Pol-II, Pol-III and RpoB (for the chloroplast) as would be expected and then this novel Pol which I have called Pol-IV.
I do not know much about RNA polymerase, but it seems like this is a pretty big deal and I think should be emphasized in the paper. What do you think? I could try to make a pretty tree figure to show the different families.
Jonathan

I got an email back:
Dear Jonathan (and Mike),
Many thanks for the detailed phylogenetic tree of the mystery pol subunit.
I think a figure is the only way to show clearly that this protein defines
a new clade. Is there room for such a figure, Mike?
In the lab we have also been calling it a putative pol IV subunit just for
the shock value of saying the words (a radical idea in the transcription
field), though in the absence of knowing what other subunits associate with
it, I’m not sure what to call it in the annotation or figure. Maybe
“oddpol” or “atypical polymerase 2nd subunit”. It takes more than a dozen
subunits to make a eukaryotic polymerase, so it is not clear that one
unusual subunit is enough to confer new properties-i.e. a true pol IV.
Obviously, that will require quite a bit of work.
Cheers,
Craig
Me to Craig on 9/11/00:
Yes
I agree that it is too early to call it a true polIV, and I was doing it for the shock value too
Jonathan
PS. Do you mind if I present this at the TIGR GSAC meeting later this week
Jonathan
Craig to me 9/11:
Hi Jonathan,
Feel free to show the data. In thinking more about this, it is worth also
making a phylogenetic tree for the largest pol subunit (the equivalent of
eubacterial B’) just to see if there might be a fourth class out there for
the largest subunit, too. If there is, pol IV may not be such a wild idea.
In case you are interested in giving this a try, I’m including some
sequences below. In the meantime, is there a good web site for performing
the types of extensive phylogenetic trees you’ve done for the mystery
subunit? I should do this for many of the general transcription factors
just to be sure they really group with the correct homologs, as you
suggested.
Anyway, here are some largest subunit sequences for pol I, II and III.
Vive la difference!
Craig
Pol I:
rat
mlaskhtpwrrlqgisfgmysaeelkklsvksitnpryvdslgnpsadglydlalgpadskevcstcvqdfnncsghlgh
idlpltvynpllfdklylllrgsclnchmltcpraaihllvcqlkvldvgalqavyelerilsrfleetsdpsafeiqee
leeytskilqnnllgsqgahvknvcesrsklvahfwkthmaakrcphcktgrsvvrkehnskltitypamvhkksgqkda
elpegapaapgideaqmgkrgyltpssaqehlfaiwknegfflnylfsglddigpessfnpsmffldfivvppsryrpin
rlgdqmftngqtvnlqavmkdavlirkllavmaqeqklpcemteitidkendssgaidrsflsllpgqsltdklyniwir
lqshvnivfdsdmdklmlekypgirqilekkeglfrkhmmgkrvdyaarsvicpdmyintneigipmvfatkltypqpvt
pwnvqelrqavingpnvhpgasmvinedgsrtalsavdatqreavakqlltpstgipkpqgakvvcrhvkngdilllnrq
ptlhrpsiqahrahilpeekvlrlhyanckaynadfdgdemnahfpqselgraeayvlactdqqylvpkdgqplagliqd
hmvsganmtirgcfftreqymelvyrgltdkvgrvklfppailkpfplwtgkqvvstlliniipedytplnltgkakigs
kawvkekprpvpdfdpdsmcesqviiregellcgvldkahygssayglvhccyeiyggetsgrvltclarlftaylqlyr
gftlgvedilvkpnadvmrqriieestqcgpravraalnlpeaascdeiqgkwqdaiwrkdqrdfnmidmkfkeevnhys
neinkacmpfglhrqfpennlqmmvqsgakgstvntmqiscllgqielegrrpplmasgkslpcfepyeftpraggfvtg
rfltgirppefffhcmagreglvdtavktsrsgylqrciikhleglviqydltvrdsdgsvvqflygedgldipktqflq
pkqfpflasnyevimkskhlhevlsradpqkvlrhfraikkwhhrhssallrkgaflsfsqkiqaavkalnlegktqngr
spetqqmlqmwheldeqsrrkyqkraapcpdpslsvwrpdihfasvsetfekkiddysqewaaqaekshnrselsldrlr
tllqlkwqrslcdpgeavgllaaqsigepstqmtlntfhfagrgemnvtlgiprlreilmvasaniktpmmsvpvfntkk
alrrvkslkkqltrvclgevlqkvdiqesfcmgekqnkfrvyelrfqflphayyqqekclrpedilhfmetrffkllmea
ikkknskasafrsvntrratqkdlddtedsgrnrreeerdeeeegnivdaeaeegdadasdtkrkekqeeevdyeseeeg
eeeeeedvqeeenikgegahqthepdeeegsgleeessqnppcrhsrpqgaeamerriqavreshsfiedyqydteeslw
cqvtvklplmkinfdmsslvvslahnaivyttkgitrcllnetinsknekefvlnteginlpelfkysevldlrrlysnd
ihavantygieaalrviekeikdvfavygiavdprhlslvadymcfegvykplnrfgiqssssplqqmtfetsfqflkqa
tmmgshdelkspsaclvvgkvvkggtglfelkqplr
Drosophila
mgskramdvhmfpsdlefavftdqeirklsvvkvitgitfdalghaipgglydirmgsygrcmdpcgtclklqdcpghmg
hielgtpvynpffikfvqrllcifclhcyklqmkdheceiimlqlrlidagyiieaqelelfkseivcqntenlvaikng
dmvhphiaamykllekneknssnstktscslrtaithsalqrlgkkcrhcnksmrfvrymhrrlvfyvtladikervgtg
aetggqnkvifadecrrylrqiyanypellkllvpvlglsntdltqgdrspvdlffmdtlpvtpprarplnmvgdmlkgn
pqtdiyiniiennhvlnvvlkymkggqeklteeakaayqtlkgetaheklytawlalqmsvdvlldvnmsremksgeglk
qiiekkcglirshmmgkrvnyaartvitpaypninvdeigipdifakklsypvpvtewnvtdvrkmvmngpdvhpganyi
qdkngfttyipadnaskreslaklllsnpkdgikivhrhvlngdvlllnrqpslhkpsimghkarilhgektfrlhysnc
kaynadfdgdemnahypqsevaraeaynlvnvasnylvpkdgtplggliqdhvisgvklsirgrffnredyqqlvfqgls
qlkkdikllpptilkpavlwsgkqilstiiiniipegyerinldsfakiagknwnvsrprppicgtnpegndlsesqvqi
rngellvgvldkqqygattyglihcmyelyggdvstllvtaftkvftfflqlegftlgvkdilvtdvadrkrrkiirecr
nvgnsavaaaleledepphdelvekmeaayvkdskfrvlldrkykslldgytndinstclprglitkfpsnnlqlmvlsg
akgsmvntmqiscllgqielegkrpplmisgkslpsftsfetspksggfidgrfmtgiqpqdfffhcmagreglidtavk
tsrsgylqrclikhleglsvhydltvrdsdnsvvqflygedgldilkskffndkfcadfltqnatailrpaqlqlmkdee
qlvkvqrhekhirswekkkpaklraafthfseelreevevkrpnevnsktgrrrfdegllklwkkadaedkalyrkkyar
cpdptvavykqdlyygsvsertrklitdyakrkpalketiadimrvktikslaapgepvgliaaqsigepstqmtlntfh
fagrgemnvtlgiprlreilmlassniktpsmdipikpgqqhqaeklrinlnsvtlanlleyvhvstgltldpersyeyd
mrfqflprevykedygvrpkhiikymhqtffkqlipppilkvsnasrttkivviddkkdadkdddndldngdevgrskak
andddssddnddddatgvklkqrktdekdyddpddveelhdanddddeaededdeekgqdgndndgddkaverllsndmv
kaytydkenhlwcqvklnlsvryqkpdltsiirelagksvvhqvqhikraiiykgndddqllktdginigemfqhnkild
lnrlysndihaiartygieaasqvivkevsnvfkvygitvdrrhlsliadymtfdgtfqplsrkgmehsssplqqmsfes
slqflksaagfgradelsspssrlmvglpvrngtgafelltkic
yeast (S.c.)
mdiskpvgseitsvdfgiltakeirnlsakqitnptvldnlghpvsgglydlalgaflrnlcstcgldekfcpghqghie
lpvpcynplffnqlyiylrasclfchhfrlksvevhryacklrllqyglidesykldeitlgslnssmytddeaiedted
emdgegskqskdisstllnelkskrseyvdmaiakalsdgrttergsftatvnderkklvhefhkkllsrgkcdncgmfs
pkfrkdgftkifetalnekqitnnrvkgfirqdmikkqkqakkldgsneasandeesfdvgrnpttrpktgstyilstev
knildtvfrkeqcvlqyvfhsrpnlsrklvkadsffmdvlvvpptrfrlpsklgeevhensqnqllskvlttsllirdln
ddlsklqkdkvsledrrvifsrlmnafvtiqndvnafidstkaqgrtsgkvpipgvkqalekkeglfrkhmmgkrvnyaa
rsvispdpnietneigvppvfavkltypepvtayniaelrqavingpdkwpgatqiqnedgslvsligmsveqrkalanq
lltpssnvsthtlnkkvyrhiknrdvvlmnrqptlhkasmmghkvrvlpnektlrlhyantgaynadfdgdemnmhfpqn
enaraealnlantdsqyltptsgspvrgliqdhisagvwltskdsfftreqyqqyiygcirpedghttrskivtlpptif
kpyplwtgkqiittvllnvtppdmpginlisknkikneywgkgslenevlfkdgallcgildksqygaskygivhslhev
ygpevaakvlsvlgrlftnyitataftcgmddlrltaegnkwrtdilktsvdtgreaaaevtnldkdtpaddpellkrlq
eilrdnnksgildavtsskvnaitsqvvskcvpdgtmkkfpcnsmqamalsgakgsnvnvsqimcllgqqalegrrvpvm
vsgktlpsfkpyetdamaggyvkgrfysgikpqeyyfhcmagreglidtavktsrsgylqrcltkqlegvhvsydnsird
adgtlvqfmyggdaiditkeshmtqfefcldnyyallkkynpsaliehldvesalkyskktlkyrkkhskephykqsvky
dpvlakynpakylgsvsenfqdklesfldknsklfkssdgvnekkfralmqlkymrslinpgeavgiiasqsvgepstqm
tlntfhfaghgaanvtlgiprlreivmtasaaiktpqmtlpiwndvsdeqadtfcksiskvllsevidkvivtettgtsn
taggnaarsyvihmrffdnneyseeydvskeelqnvisnqfihlleaaivkeikkqkrttgpdigvavprlqtdvansss
nskrleedndeeqshkktkqavsydepdedeietmreaekssdeegidsdkesdsdsededvdmneqinksiveannnmn
kvqrdrqsaiishhrfitkynfddesgkwcefklelaadtekllmvniveeicrksiirqiphidrcvhpepengkrvlv
tegvnfqamwdqeafidvdgitsndvaavlktygveaarntivneinnvfsryaisvsfrhldliadmmtrqgtylafnr
qgmetstssfmkmsyettcqfltkavldnereqldspsarivvgklnnvgtgsfdvlakvpnaa
Arabidopsis
MAHAQTTEVCLSFHRSLLFPMGASQVVESVRFSFMTEQDVRKHSFLKVTSPILHDNVGNPFPGGLYDLKLGPKDDKQACN
SCGQLKLACPGHCGHIELVFPIYHPLLFNLLFNFLQRACFFCHHFMAKPEDVERAVSQLKLIIKGDIVSAKQLESNTPTK
SKSSDESCESVVTTDSSEECEDSDVEDQRWTSLQFAEVTAVLKNFMRLSSKSCSRCKGINPKLEKPMFGWVRMRAMKDSD
VGANVIRGLKLKKSTSSVENPDGFDDSGIDALSEVEDGDKETREKSTEVAAEFEEHNSKRDLLPSEVRNILKHLWQNEHE
FCSFIGDLWQSGSEKIDYSMFFLESVLVPPTKFRPPTTGGDSVMEHPQTVGLNKVIESNNILGNACTNKLDQSKVIFRWR
NLQESVNVLFDSKTATVQSQRDSSGICQLLEKKEGLFRQKMMGKRVNHACRSVISPDPYIAVNDIGIPPCFALKLTYPER
VTPWNVEKLREAIINGPDIHPGATHYSDKSSTMKLPSTEKARRAIARKLLSSRGATTELGKTCDINFEGKTVHRHMRDGD
IVLVNRQPTLHKPSLMAHKVRVLKGEKTLRLHYANCSTYNADFDGDEMNVHFPQDEISRAEAYNIVNANNQYARPSNGEP
LRALIQDHIVSSVLLTKRDTFLDKDHFNQLLFSSGVTDMVLSTFSGRSGKKVMVSASDAELLTVTPAILKPVPLWTGKQV
ITAVLNQITKGHPPFTVEKATKLPVDFFKCRSREVKPNSGDLTKKKEIDESWKQNLNEDKLHIRKNEFVCGVIDKAQFAD
YGLVHTVHELYGSNAAGNLLSVFSRLFTVFLQTHGFTCGVDDLIILKDMDEERTKQLQECENVGERVLRKTFGIDVDVQI
DPQDMRSRIERILYEDGESALASLDRSIVNYLNQCSSKGVMNDLLSDGLLKTPGRNCISLMTISGAKGSKVNFQQISSHL
GQQDLEGKRVPRMVSGKTLPCFHPWDWSPRAGGFISDRFLSGLRPQEYYFHCMAGREGLVDTAVKTSRSGYLQRCLMKNL
ESLKVNYDCTVRDADGSIIQFQYGEDGVDVHRSSFIEKFKELTINQDMVLQKCSEDMLSGASSYISDLPISLKKGAEKFV
EAMPMNERIASKFVRQEELLKLVKSKFFASLAQPGEPVGVLAAQSVGEPSTQMTLNTFHLAGRGEMNVTLGIPRLQEILM
TAAANIKTPIMTCPLLKGKTKEDANDITDRLRKITVADIIKSMELSVVPYTVYENEVCSIHKLKINLYKPEHYPKHTDIT
EEDWEETMRAVFLRKLEDAIETHMKMLHRIRGIHNDVTGPIAGNETDNDDSVSGKQNEDDGDDDGEGTEVDDLGSDAQKQ
KKQETDEMDYEENSEDETNEPSSISGVEDPEMDSENEDTEVSKEDTPEPQEESMEPQKEVKGVKNVKEQSKKKRRKFVRA
KSDRHIFVKGEGEKFEVHFKFATDDPHILLAQIAQQTAQKVYIQNSGKIERCTVANCGDPQVIYHGDNPKERREISNDEK
KASPALHASGVDFPALWEFQDKLDVRYLYSNSIHDMLNIFGVEAARETIIREINHVFKSYGISVSIRHLNLIADYMTFSG
GYRPMSRMGGIAESTSPFCRMTFETATKFIVQAATYGEKDTLETPSARICLGLPALSGTGCFDLMQRVEL
Pol II:
Arabidopsis
mdtrfpfspaevskvrvvqfgilspdeirqmsvihvehsettekgkpkvgglsdtrlgtidrkvkcetcmanmaecpghf
gylelakpmyhvgfmktvlsimrcvcfncskiladeamkiknpknrlkkildacknktkcdggddiddvqshstdepvkk
srggcgaqqpkltiegmkmiaeyknskeendepdqlpepaerkqtlgadrvlsvlkrisdadcqllgfnpkfarpdwmil
evlpippppvrpsvmmdatsrseddlthqlamiirhnenlkrqekngaprhiisrftqllqfhiatyfdnelpgqpratq
ksgrpiksicsrlkakegrirgnlmgkrvdfsartvitpdptinidelgvpwsialnltypetvtpynierlkelvdygp
hpppgktgakyiirddgqrldlrylkkssdqhlelgyryvllsysihsthkrlflevvifmlswsqverhlqdgdfvlfn
rqpslhkmsimghririmpystfrlnlsvtspynadfdgdemnmhvpqsfetraevlelmmvpkcivspqanrpvmgivq
dtllgcrkitkrdtfiekdvfmntlmwwedfdgkvpapailkprplwtgkqvfnliipkqinllrysawhadtetgfitp
gdtqvriergellagtlckktlgtsngslvhviweevgpdaarkflghtqwlvnywllqngftigigdtiadsstmekin
etisnaktavkdlirqfqgkeldpepgrtmrdtfenrvnqvlnkarddagssaqkslaetnnlkamvtagskgsfinisq
mtacvgqqnvegkripfgfdgrtlphftkddygpesrgfvensylrgltpqefffhamggreglidtavktsetgyiqrr
lvkamedimvkydgtvrnslgdviqflygedgmdavwiesqkldslkmkksefdrtfkyeiddenwnptylsdehledlk
girelrdvfdaeyskletdrfqlgteiatngdstwplpvnikrhiwnaqktfkidlrkisdmhpveivdavdklqerllv
vpgddalsveaqknatlffnillrstlaskrvleeyklsreafewvigeiesrflqslvapgemigcvpaqsigepatqm
tlntfhyagvsaknvtlgvprlreiinvakriktpslsvyltpeaskskegaktvqcaleyttlrsvtqatevwydpdpm
stiieedfefvrsyyempdedvspdkispwllrielnremmvdkklsmadiaekinlefdddltcifnddnaqklilrir
imndegpkgelqdesaeddvflkkiesnmltemalrgipdinkvfikqvrksrfdeeggfktseewmldtegvnllavmc
hedvdpkrttsnhlieiievlgieavrralldelrvvisfdgsyvnyrhlailcdtmtyrghlmaitrhginrndtgplm
rcsfeetvdilldaaayaetdclrgvtenimlgqlapigtgdcelylndemlknaielqlpsymdglefgmtparspvsg
tpyhegmmspnyllspnmrlspmsdaqfspyvggmafspssspgyspsspgysptspgysptspgysptspgysptspty
spsspgysptspaysptspsysptspsysptspsysptspsysptspsysptspsysptspaysptspaysptspayspt
spsysptspsysptspsysptspsysptspsysptspaysptspgysptspsysptspsygptspsynpqsakyspsiay
spsnarlspaspysptspnysptspsysptspsyspssptyspsspyssgaspdyspsagysptlpgyspsstgqytphe
gdkkdktgkkdaskddkgnp
Drosophila
mstptdskaplrqvkrvqfgilspdeirrmsvteggvqfaetmeggrpklgglmdprqgvidrtsrcqtcagnmtecpgh
fghidlakpvfhigfitktikilrcvcfycskmlvsphnpkikeivmksrgqprkrlayvydlckgkticeggedmdltk
enqqpdpnkkpghggcghyqpsirrtgldltaewkhqnedsqekkivvsaervweilkhitdeecfilgmdpkyarpdwm
ivtvlpvpplavrpavvmfgaaknqddlthklsdiikannelrkneasgaaahviqenikmlqfhvatlvdndmpgmpra
mqksgkplkaikarlkgkegrirgnlmgkrvdfsartvitpdpnlridqvgvprsiaqnltfpelvtpfnidrmqelvrr
gnsqypgakyivrdngeridlrfhpkssdlhlqcgykverhlrdddlvifnrqptlhkmsmmghrvkvlpwstfrmnlsc
tspynadfdgdemnlhvpqsmetraevenihitprqiitpqankpvmgivqdtltavrkmtkrdvfitreqvmnllmflp
twdakmpqpcilkprplwtgkqifsliipgnvnmirthsthpdeedegpykwispgdtkvmvehgelimgilckkslgts
agsllhicflelghdiagrfygniqtvinnwllfeghsigigdtiadpqtyneiqqaikkakddvinviqkahnmelept
pgntlrqtfenkvnrilndahdktggsakkslteynnlkamvvsgskgsninisqviacvgqqnvegkripygfrkrtlp
hfikddygpesrgfvensylagltpsefyfhamggreglidtavktaetgyiqrrlikamesvmvnydgtvrnsvgqliq
lrygedglcgelvefqnmptvklsnksfekrfkfdwsnerlmkkvftddvikemtdsseaiqeleaewdrlvsdrdslrq
ifpngeskvvlpcnlqrmiwnvqkifhinkrlptdlspirvikgvktllercvivtgndriskqanenatllfqclirst
lctkyvseefrlsteafewlvgeietrfqqaqanpgemvgalaaqslgepatqmtlntfhfagvssknvtlgvprlkeii
niskkpkapsltvfltggaardaekaknvlcrlehttlrkvtantaiyydpdpqrtvisedqefvnvyyempdfdptris
pwllrieldrkrmtdkkltmeqiaekinvgfgedlncifnddnadklvlririmnneenkfqdedeavdkmeddmflrci
eanmlsdmtlqgieaigkvymhlpqtdskkrivitetgefkaigewlletdgtsmmkvlserdvdpirtssndiceifqv
lgieavrksvekemnavlqfyglyvnyrhlallcdvmtakghlmaitrhginrqdtgalmrcsfeetvdvlmdaaahaet
dpmrgvseniimgqlpkmgtgcfdllldaekcrfgieipntlgnsmlggaamfigggstpsmtppeldsawancntpryf
sppghvsamtpggpsfspsaasdasgmspswspahpgsspsspgpsmspyfpaspsvspsysptspnytasspggaspny
spsspnysptsplyaspryasttpnfnpqstgyspsssgysptspvysptvqfqsspsfagsgsniyspgnayspsssny
spnspsysptspsyspsspsysptspcysptspsysptspnytpvtpsysptspnysaspqyspaspaysqtgvkyspts
ptysppspsydgspgspqytpgspqyspaspkysptsplyspsspqhspsnqysptgstysatspryspnmsiyspsstk
ysptsptytptarnysptspmysptapshysptspayspssptfeesedvrkggrg
human
mhgggppsgdsacplrtikrvqfgvlspdelkrmsvteggikypetteggrpklgglmdprqgviertgrcqtcagnmte
cpghfghielakpvfhvgflvktmkvlrcvcffcskllvdsnnpkikdilakskgqpkkrlthvydlckgkniceggeem
dnkfgveqpegdedltkekghggcgryqprirrsglelyaewkhvnedsqekkillspervheifkrisdeecfvlgmep
ryarpewmivtvlpvpplsvrpavvmqgsarnqddlthkladivkinnqlrrneqngaaahviaedvkllqfhvatmvdn
elpglpramqksgrplkslkqrlkgkegrvrgnlmgkrvdfsartvitpdpnlsidqvgvprsiaanmtfaeivtpfnid
rlqelvrrgnsqypgakyiirdngdridlrfhpkpsdlhlqtgykverhmcdgdivifnrqptlhkmsmmghrvrilpws
tfrlnlsvttpynadfdgdemnlhlpqsletraeiqelamvprmivtpqsnrpvmgivqdtltavrkftkrdvflergev
mnllmflstwdgkvpqpailkprplwtgkqifsliipghincirthsthpddedsgpykhispgdtkvvvengelimgil
ckkslgtsagslvhisylemghditrlfysniqtvinnwllieghtigigdsiadsktyqdiqntikkakqdvievieka
hnneleptpgntlrqtfenqvnrilndardktgssaqkslseynnfksmvvsgakgskinisqviavvgqqnvegkripf
gfkhrtlphfikddygpesrgfvensylagltptefffhamggreglidtavktaetgyiqrrliksmesvmvkydatvr
nsinqvvqlrygedglagesvefqnlatlkpsnkafekkfrfdytneralrrtlqedlvkdvlsnahiqnelerefermr
edrevlrvifptgdskvvlpcnllrmiwnaqkifhinprlpsdlhpikvvegvkelskklvivngddplsrqaqenatll
fnihlrstlcsrrmaeefrlsgeafdwllgeieskfnqaiahpgemvgalaaqslgepatqmtlntfhyagvsaknvtlg
vprlkeliniskkpktpsltvfllgqsardaerakdilcrlehttlrkvtantaiyydpnpqstvvaedqewvnvyyemp
dfdvarispwllrveldrkhmtdrkltmeqiaekinagfgddlncifnddnaeklvlririmnsdenkmqeeeevvdkmd
ddvflrciesnmltdmtlqgieqiskvymhlpqtdnkkkiiitedgefkalqewiletdgvslmrvlsekdvdpvrttsn
diveiftvlgieavrkalerelyhvisfdgsyvnyrhlallcdtmtcrghlmaitrhgvnrqdtgplmkcsfeetvdvlm
eaaahgesdpmkgvsenimlgqlapagtgcfdllldaekckygmeiptnipglgaagptgmffgsapspmggispamtpw
nqgatpaygawspsvgsgmtpgaagfspsaasdasgfspgyspawsptpgspgspgpsspyipspggamspsysptspay
eprspggytpqspsysptspsysptspsysptspnysptspsysptspsysptspsysptspsysptspsysptspsysp
tspsysptspsysptspsysptspsysptspsysptspsysptspsysptspsysptspsysptspnysptspnytptsp
sysptspsysptspnytptspnysptspsysptspsysptspsyspssprytpqsptytpsspsyspsspsysptspkyt
ptspsyspsspeytpaspkysptspkysptspkysptsptyspttpkysptsptysptspvytptspkysptsptyspts
pkysptsptysptspkgstysptspgysptsptysltspaispddsdeen
yeast (S.c)
mvgqqyssaplrtvkevqfglfspeevraisvakirfpetmdetqtrakigglndprlgsidrnlkcqtcqegmnecpgh
fghidlakpvfhvgfiakikkvcecvcmhcgkllldehnelmrqalaikdskkrfaaiwtlcktkmvcetdvpseddptq
lvsrggcgntqptirkdglklvgswkkdratgdadepelrvlsteeilnifkhisvkdftslgfnevfsrpewmiltclp
vppppvrpsisfnesqrgeddltfkladilkanisletlehngaphhaieeaesllqfhvatymdndiagqpqalqksgr
pvksirarlkgkegrirgnlmgkrvdfsartvisgdpnleldqvgvpksiaktltypevvtpynidrltqlvrngpnehp
gakyvirdsgdridlryskragdiqlqygwkverhimdndpvlfnrqpslhkmsmmahrvkvipystfrlnlsvtspyna
dfdgdemnlhvpqseetraelsqlcavplqivspqsnkpcmgivqdtlcgirkltlrdtfieldqvlnmlywvpdwdgvi
ptpaiikpkplwsgkqilsvaipngihlqrfdegttllspkdngmliidgqiifgvvekktvgssngglihvvtrekgpq
vcaklfgniqkvvnfwllhngfstgigdtiadgptmreitetiaeakkkvldvtkeaqanlltakhgmtlresfednvvr
flneardkagrlaevnlkdlnnvkqmvmagskgsfiniaqmsacvgqqsvegkriafgfvdrtlphfskddyspeskgfv
ensylrgltpqefffhamggreglidtavktaetgyiqrrlvkaledimvhydnttrnslgnviqfiygedgmdaahiek
qsldtiggsdaafekryrvdllntdhtldpsllesgseilgdlklqvlldeeykqlvkdrkflrevfvdgeanwplpvni
rriiqnaqqtfhidhtkpsdltikdivlgvkdlqenllvlrgkneiiqnaqrdavtlfccllrsrlatrrvlqeyrltkq
afdwvlsnieaqflrsvvhpgemvgvlaaqsigepatqmtlntfhfagvaskkvtsgvprlkeilnvaknmktpsltvyl
epghaadqeqaklirsaiehttlksvtiaseiyydpdprstvipedeeiiqlhfslldeeaeqsfdqqspwllrleldra
amndkdltmgqvgerikqtfkndlfviwsedndekliircrvvrpksldaeteaeedhmlkkientmlenitlrgvenie
rvvmmkydrkvpsptgeyvkepewvletdgvnlsevmtvpgidptriytnsfidimevlgieagraalykevynviasdg
syvnyrhmallvdvmttqggltsvtrhgfnrsntgalmrcsfeetveilfeagasaelddcrgvsenvilgqmapigtga
fdvmideeslvkympeqkiteiedgqdggvtpysnesglvnadldvkdelmfsplvdsgsndamaggftayggadygeat
spfgaygeaptspgfgvsspgfsptsptysptspaysptspsysptspsysptspsysptspsysptspsysptspsysp
tspsysptspsysptspsysptspsysptspsysptspsysptspsysptspsysptspaysptspsysptspsysptsp
sysptspsysptspnysptspsysptspgyspgspayspkqdeqkhnenensr
pol III:
human
mvkeqfretdvakktshicfgmkspeemrqqahiqvvsknlysqdnqhapllygvldhrmgtsekdrpcetcgknladcl
ghygyidlelpcfhvgyfravigilqmicktcchimlsqeekkqfldylkrpgltylqkrglkkkisdkcrkknichhcg
afngtvkkcgllkiihekyktnkkvvdpivsnflqsfetaiehnkevepllgraqenlnplvvlnlfkripaedvplllm
npeagkpsdliltrllvpplcfrpsvvsdlksgtneddltmklteiiflndvikkhrisgaktqmimedwdflqlqcaly
inselsgiplnmapkkwtrgfvqrlkgkqgrfrgnlsgkrvdfsgrtvispdpnlridevavpvhvakiltfpekvnkan
inflrklvqngpevhpganfiqqrhtqmkrflkygnrekmaqelkygdiverhlidgdvvlfnrqpslhklsimahlarv
kphrtfrfnecvctpynadfdgdemnlhlpqteeakaealvlmgtkanlvtprngepliaaiqdfltgaylltlkdtffd
rakacqiiasilvgkdekikvrlppptilkpvtlwtgkqifsvilrpsddnpvranlrtkgkqycgkgedlcandsyvti
qnselmsgsmdkgtlgsgsknnifyillrdwgqneaadamsrlarlapvylsnrgfsigigdvtpgqgllkakyellnag
ykkcdeyiealntgklqqqpgctaeetlealilkelsvirdhagsaclreldksnspltmalcgskgsfinisqmiacvg
qqaisgsrvpdgfenrslphfekhsklpaakgfvansfysgltptefffhtmagreglvdtavktaetgymqrrlvksle
dlcsqydltvrsstgdiiqfiyggdgldpaamegkdeplefkrvldnikavfpcpsepalsknelilttesimkkseflc
cqdsflqeikkfikgvsekikktrdkygindngtteprvlyqldritptqvekfletcrdkymraqmepgsavgalcaqs
igepgtqmtlktfhfggvasmnitlgvprikeiinaskaistpiitaqldkdddadyarlvkgriektllgeiseyieev
flpddcfilvklslerirllrlevnaetvrysictsklrvkpgdvavhgeavvcvtprenskssmyyvlqflkedlpkvv
vqgipevsravihideqsgkekykllvegdnlravmathgvkgtrttsnntyevektlgieaarttiineiqytmvvnhg
msidrrhvmllsdlmtykgevlgitrfglakmkesvlmlasfektadhlfdaayfgqkdsvcgvseciimgipmnigtgl
fkllhkadrdpnppkrplifdtnefhiplvt
trypanosome
mlkgssstsfllpqqfveplphapveisalhygllsrndvhrlsvlpcrrvvgdvkeygvndarlgvcdrlsicetcgln
siecvghpghidleapvfhlgffttvlricrtickrcshvllddteidyykrrlssssleplqrtmliktiqtdayktrv
clkcgglngvvrrvrpmrlvhekyhveprrgegprenpggffdaelrtacaynkvvgecrefvhdfldpvrvrqlflavp
pgevillglapgvsptdllmttllvppvpvrprgcagtttvrdddltaqyndilvstdtmqdgsldatrytetwemlqmr
aarlldsslpgfppnvrtsdlksyaqrlkskhgrfrcnlsgkrvdysgrsvispdpnldvdelavplhvarvltypqrvf
kanhelmrrlvrngphvhpgattvylaqegskkslknerdrhrlaarlavgdiverhvmngdlvlfnrqpslhrvsmmah
rarvlpfrtfrfnecccapynadfdgdemnvhfvqtekaraealqlmstarniisakngepiiactqdflaaaylvtsrd
vffdrgefsqmvshwlgpvtqfrlpipailkpvelwtgkqlfelivrpspevdvllsfeaptkfytrkgkhdcaeegyva
fldscfisgrldkkllgggakdglfarlhtiagggytarvmsriaqftsryltnygfslglgdvaptpelnkqkaavlar
svevcdgliksaktgrmiplpgltvkqslearlntelskvrdecgtaavqtlsihnntplimvqsgskgsalniaqmmac
vgqqtvsgkrildafqdrslphfhrfeeapaargfvansfysglsptefffhtmagreglvdtavktaetgyiyrrlmka
menlsvrydgtvrntkgdviqlrfgedgldpqlmegnsgtplnleqewlsvraayarwvvgllagsktasdgnairdnen
yfnefismlptegpsfveaclngdqealkvceeqesredalhnsngktndresrprtgrlrravlishlvkvcsrkfkdd
iqdffvkkvreqqrirnllnlpntsrertegggdnsgpiankrtkkrapslkvkdskeggrvselrdlemlqtellpltr
gmvtrfiaqcaskylrkacepgtpcgaiaaqsvgepstqmtlrtfhfagvasmsitqgvprlvevinanrniatpvvtap
vllmegeenhceifrkrarfvkaqiervllrevvseivevcsdtefylrvhlnmsvitklhlpinaitvrqrilaaaght
msplrmlnedcievfsldtlavyphfqdarwvhfslrrilgllpdvvvggigginramissngtevlaegaelravmnlw
gvdstrvvcnhvavvervlgieaarrvivdeiqnilkayslsidvrhvylladlmtqrgvvlgitrygiqkmnfnvltma
sferttdhlynaaatqrvdrdlsvsdsiivgkpvplgttsfdllldgsisndilppqrcvkrgmgpnfhtakrhhlvpla
aegvfrldlf
yeast (S.c)
mkevvvsetpkrikglefsalsaadivaqsevevstrdlfdlekdrapkangaldpkmgvsssslecatchgnlaschgh
fghlklalpvfhigyfkatiqilqgickncsaillsetdkrqflhelrrpgvdnlrrmgilkkildqckkqrrclhcgal
ngvvkkaaagagsaalkiihdtfrwvgkksapekdiwvgewkevlahnpeleryvkrcmddlnplktlnlfkqiksadce
llgidatvpsgrpetyiwrylpappvcirpsvmmqdspasneddltvklteivwtsslikagldkgisinnmmehwdylq
ltvamyinsdsvnpamlpgssngggkvkpirgfcqrlkgkqgrfrgnlsgkrvdfsgrtvispdpnlsidevavpdrvak
vltypekvtrynrhklqelivngpnvhpganyllkrnedarrnlrygdrmklaknlqigdvverhledgdvvlfnrqpsl
hrlsilshyakirpwrtfrlnecvctpynadfdgdemnlhvpqteearaeainlmgvknnlltpksgepiiaatqdfitg
sylishkdsfydratltqllsmmsdgiehfdipppaimkpyylwtgkqvfsllikpnhnspvvinldaknkvfvppksks
lpnemsqndgfviirgsqilsgvmdksvlgdgkkhsvfytilrdygpqeaanamnrmaklcarflgnrgfsigindvtpa
ddlkqkkeelveiayhkcdelitlfnkgeletqpgcneeqtleakiggllskvreevgdvcineldnwnaplimatcgsk
gstlnvsqmvavvgqqiisgnrvpdgfqdrslphfpknsktpqskgfvrnsffsglsppeflfhaisgreglvdtavkta
etgymsrrlmksledlscqydntvrtsangivqftyggdgldplemegnaqpvnfnrswdhaynitfnnqdkgllpyaim
etaneilgpleerlvrydnsgclvkredlnkaeyvdqydaerdfyhslreyingkatalanlrksrgmlglleppakelq
gidpdetvpdnvktsvsqlyriseksvrkfleialfkyrkarlepgtaigaigaqsigepgtqmtlktfhfagvasmnvt
lgvprikeiinaskvistpiinavlvndnderaarvvkgrvektllsdvafyvqdvykdnlsfiqvridlgtidklqlel
tiediavaitrasklkiqasdvniigkdriainvfpegykaksistsakepsendvfyrmqqlrralpdvvvkglpdisr
avinirddgkrellvegyglrdvmctdgvigsrtttnhvlevfsvlgieaarysiireinytmsnhgmsvdprhiqllgd
vmtykgevlgitrfglskmrdsvlqlasfekttdhlfdaafymkkdavegvseciilgqtmsigtgsfkvvkgtnisekd
lvpkrclfeslsneaalkan
9/11 me to Craig
sorry .. no useful sites out there for doing phylogenetic analysis … I am working on such a type of thing right now. I tis tricky becuase to do it correctly you need to filter out parts of a multiple sequence alignment to remove badly aligned regions as well as hypervariable regions.
9/12 Craig to Me
Dear Mike,
Yes, I can do this for the atypical RNA polymerase 2nd subunit. I have
already done multiple alignments with it against pol I, II, III subunits
and it is clear that the atypical subunit has amino acid differences that
set it apart, rather than large indels that skew the data. So I think
Jonathan is safe to go ahead and make a figure while I examine the gene
sequences and gene models more carefully.
Any comments on the tone/amount of detail in the section I wrote on the
general transcription machinery? Either way, I will add some references
and send you an updated version as soon as I can.
cheers
Craig
———————
>Speaking on behalf of the editorial committee whom I have not consulted, I
>would be delighted to have this in our section. But we need to check out the
>gene structure in detail (dodgy gene prediction, missing exons etc. Craig,
>could you so this as you know most about these enzymes
>
>All the best
>
>Mike
Me to Craig
Craig
I am still working on a slightly better figure … but I have attached the latest version … I think it is sufficient for submission
I have attached it in a few different formats.
I will be out of town for a few days but checking email.
Jonathan
Craig to Me:
Hi Jonathan,
The phytlogenetic tree figure for the atypical pol subunit looks good
though the font size may need to be reduced to fit “Fungal Plasmids”
between the dividing lines for the adjacent categories. Have you sent a
copy to Mike?
Craig
Craig again
Hi Jonathan,
I forwarded a copy to Mike. Did you ever have a chance to do a tree for the
largest subunit to further test the hypothesis of a pol IV?
Hope you are having fun in LA
Craig
> I am not sure if I sent a copy to mike
>
>I am in LA right now and it would be easier if you could send mike a copy to
>make sure he has one. I will try and edit the figure and send one with a
>smaller font.
>
>J
10/3 Me to Craig:
Criag
Attached is a new version of the rna pol tree with fonts corrected. I am going to add a few more sequences a rerun it and make a new tree tomorrow.
Jonathan
PS Also … here is a potential figure legend
Figure. Phylogenetic tree of RNA polymerase homologs. Homologs of RNA polymerase were identified by searching sequence databases with representatives of the major known RNA polymerase subfamilies. These proteins, as well as six DNA polymerase homologs from A. thaliana, were aligned using clustalx using default settings. Phylogenetic trees were generated from the alignment (with ambiguously aligned regions and hypervariable regions excluded) using the PAUP* program. The tree shows was generated using the neighbor-joining algorithm with pairwise distances between sequences calculated with a PAM-like matrix. Numbers on the branches are bootstrap values indicating the percentage of 100 trees in which the proteins to the right of the node grouped together to the exclusion of all other proteins.
Craig 10/3
Hi Jonathan,
I will look forward to seeing the final tree, as will Mike, I’m sure. For
the legend, the fact that this is an alignment of second-largest subunits
should be made clear. Here is a stab at a minor revision:
Figure—–. Phylogenetic tree for the second-largest subunit of
DNA-dependent RNA polymerases. Homologs of RNA polymerase second-largest
subunits were identified by searching sequence databases with
representatives of the major known subfamilies (e.g. pol I, II, III and
eubacterial beta subunits). Identified proteins, including six homologs
from A. thaliana, were
aligned using clustalx using default settings. Phylogenetic trees were
generated from the alignment (with ambiguously aligned regions and
hypervariable regions excluded) using the PAUP* program. The treewas generated using the neighbor-joining algorithm with pairwise distances
between sequences calculated with a PAM-like matrix. Numbers on the
branches are bootstrap values indicating the percentage of 100 trees inwhich the proteins to the right of the node group together to the
exclusion of all other proteins.
Thanks,
Craig
Me:
much better figure legend
j
Anyway – and so it went. Alas, for a variety of reasons not much made it into the final paper. What was there was this:
Unexpectedly, Arabidopsis has two genes encoding a fourth class of largest subunit and second-largest subunit (Supplementary Information Fig. 5). It will be interesting to determine whether the atypical subunits comprise a polymerase that has a plant-specific function.
And of course, this Supplemental Information is not exactly easy to find and does not actually work correctly anymore:

Downloading the Zip file and opening first page.htm gets one to this
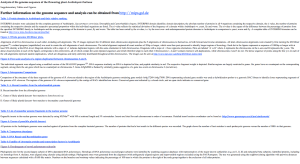
And then clicking on the Figure 5 you get a broken page w/o the Figure.

But there, hidden in the folder with the Supplemental Information is the figure

So that is the beginning of the story on RNA Pol IV in Arabidopsis.
Go read the E-life paper and some of what it cites for the last 15 years of the story.